-
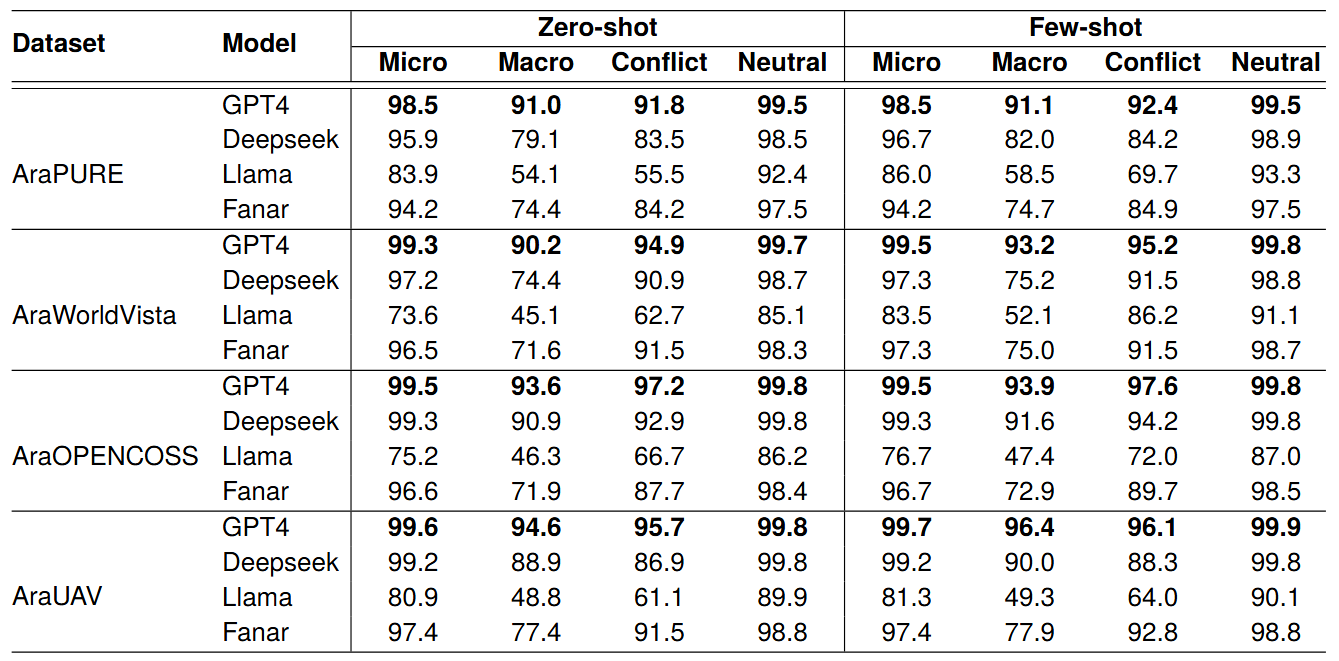
Evaluation of 4 LLMsWe evaluate GPT-4o, Fanar, DeepSeek-Reasoner, and LLaMA 3.1 8B Instruct. The models are evaluated on four datasets (PURE, WorldVista, OPENCOSS, and UAV) under zero-shot and few-shot settings. See article [1] for details.
-
GitHub: Evaluation source code.
AraREQ Datasets (Datasets only) -
Tymaa Hammouda, Alaa Aljabari, Nagham Hamad, Mustafa Jarrar: AraREQ: A Dataset and End-to-End Conflict Detection and Resolution in Software Requirements. In Proceedings of the 2026 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2026), Palma, Mallorca (Spain).